
(1) Analysis of bucket tooth data training results of model bucket
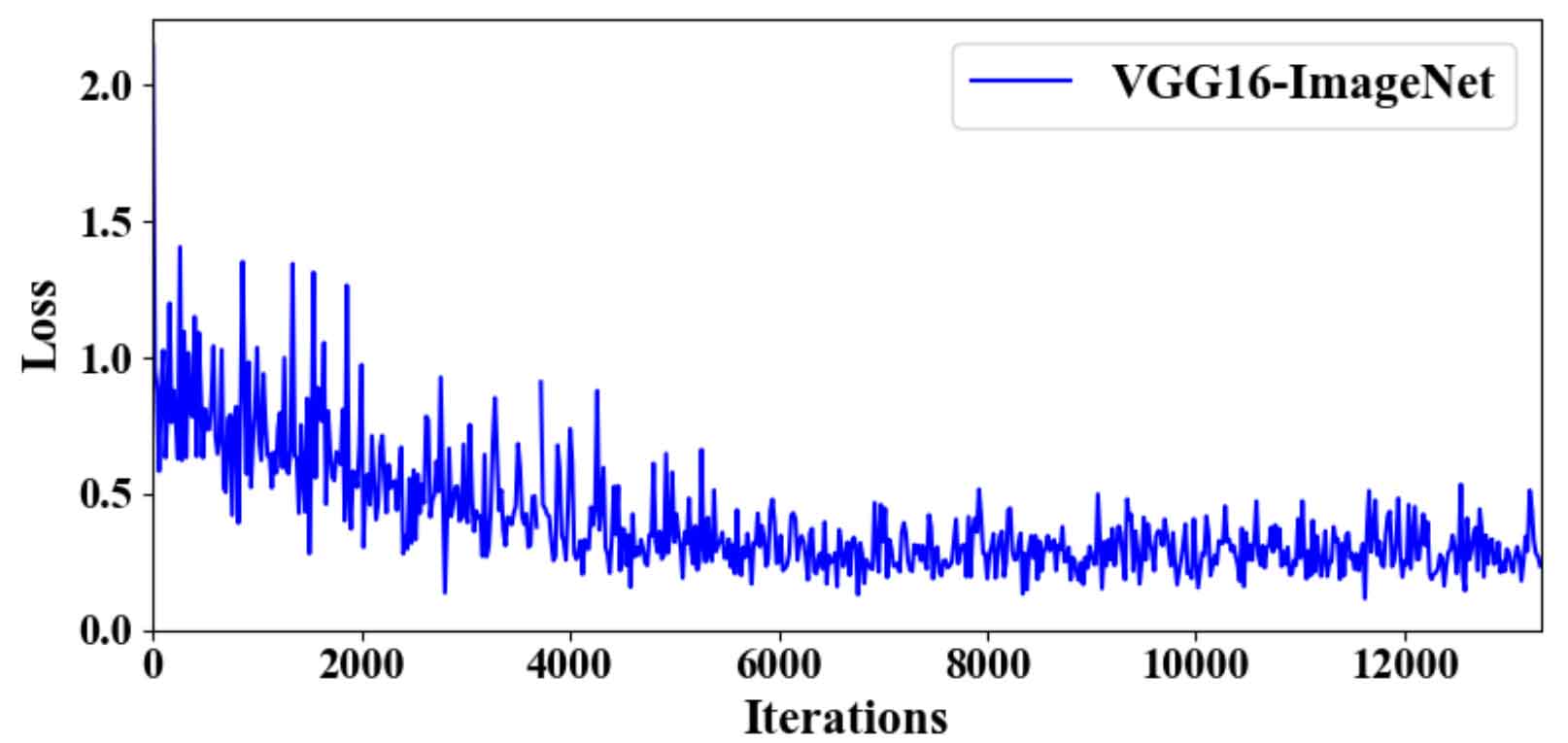
From the perspective of loss change, the overall trend of the three network loss changes is first decreasing, then stable, and there are large fluctuations in some later stages. Comparing Fig. 1, Fig. 2 and Fig. 3, it can be seen that when vgg16 is selected as the feature extraction network, the loss is large at the beginning of the training process, and the loss changes tend to be stable with the increase of training times; Because zfnet has few feature extraction layers and small parameter scale, it has a large loss for some difficult samples in the network training stage; Resnet-50 belongs to a large-scale deep network, and the number of parameters is too large. Therefore, in the early training process, the loss fluctuates greatly.
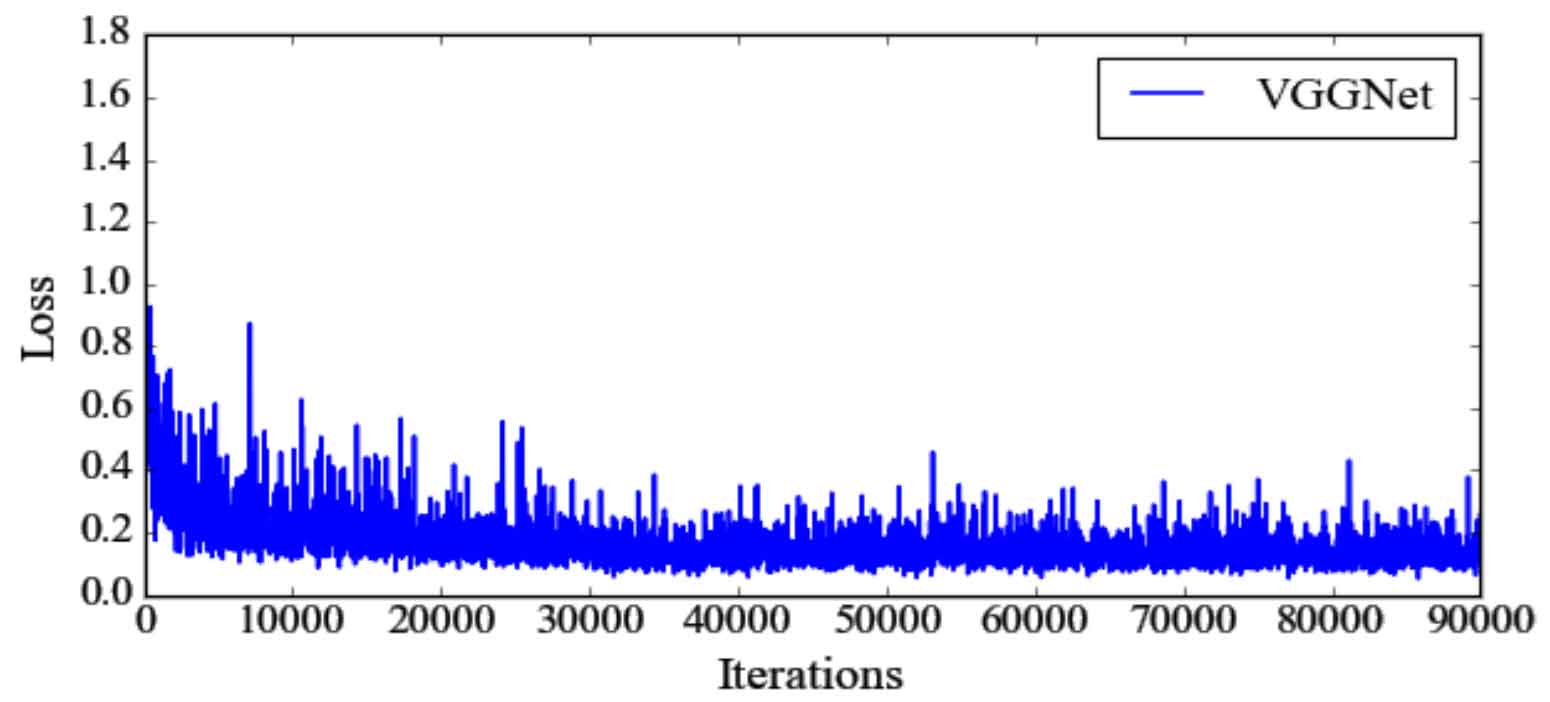
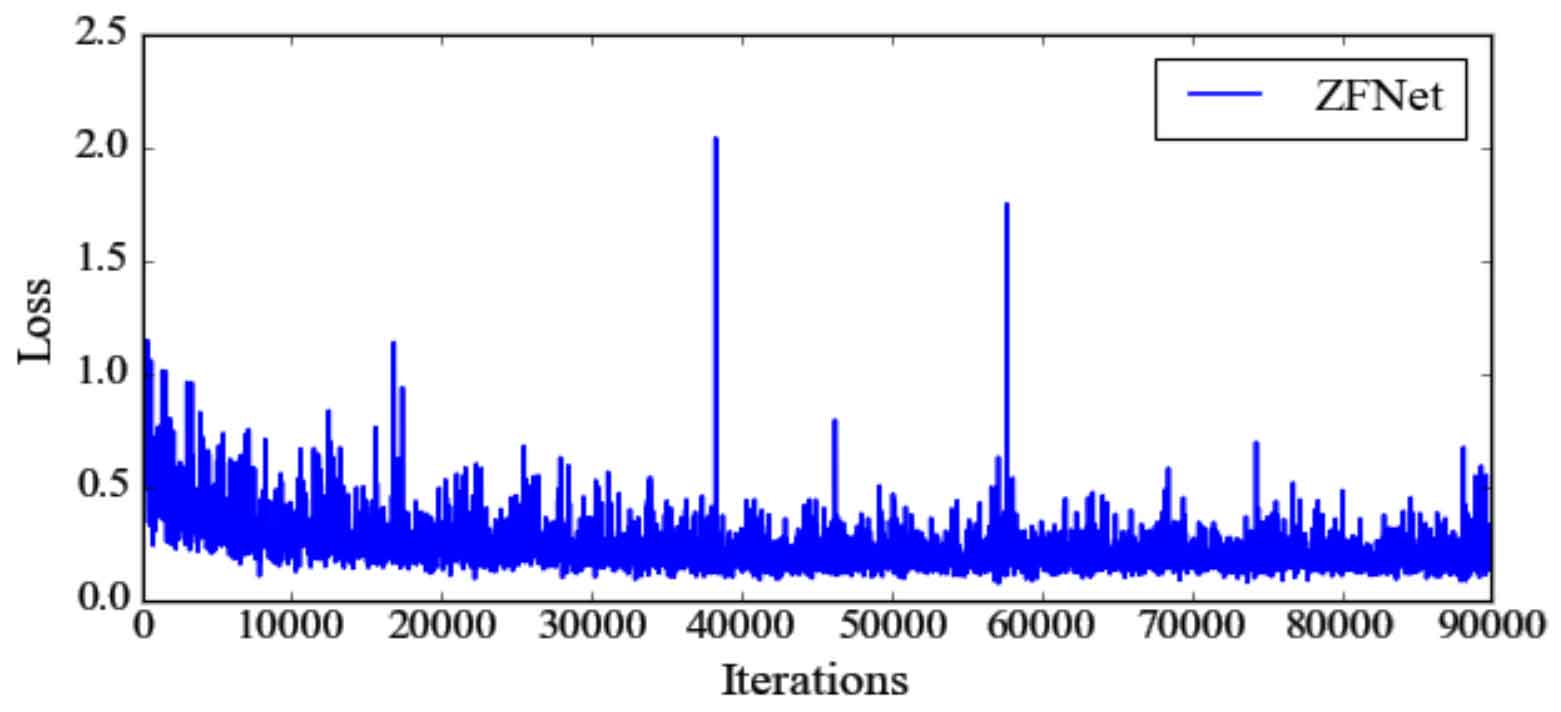
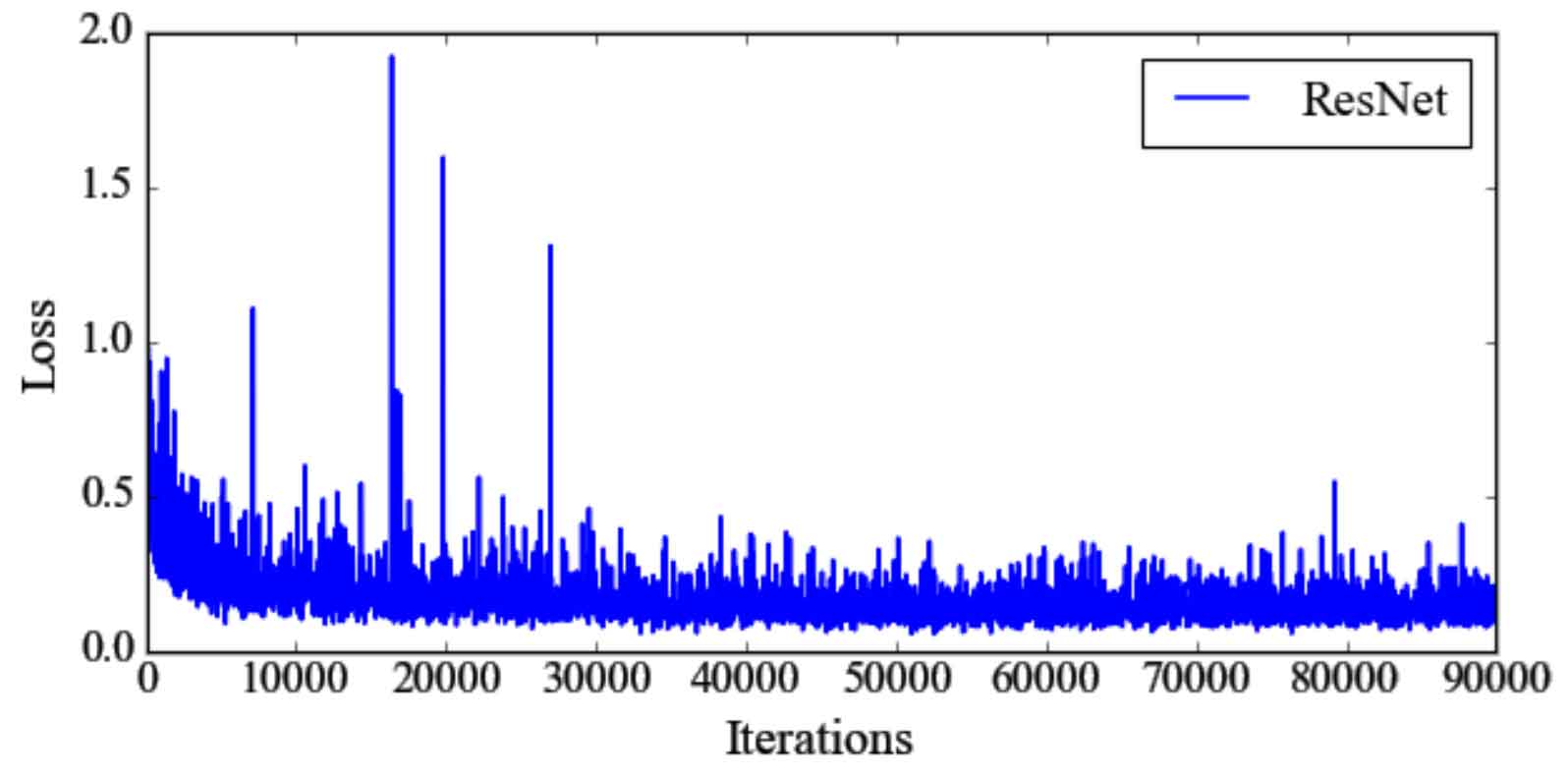
From the indicators of target detection, the effect of vgg16 is better than the other two feature extraction networks. When the step size is equal to 60000, the index value of each feature extraction network is basically not improved. It can be seen from table 1 that the effect of vgg16 is slightly better than resnet-50, and the calculation time is less than resnet-50. In conclusion, it is reasonable to choose vgg16 as the feature extraction network.
| Feature extraction network | AP | Recall | Precision | Time |
| VGG16 | 0.9085 | 0.9962 | 0.9124 | 0.071s |
| ZFNet | 0.9068 | 0.9939 | 0.672 | 0.042s |
| ResNet-50 | 0.9078 | 0.9959 | 0.8471 | 0.161s |
(2) Analysis of bucket tooth data training results of actual bucket
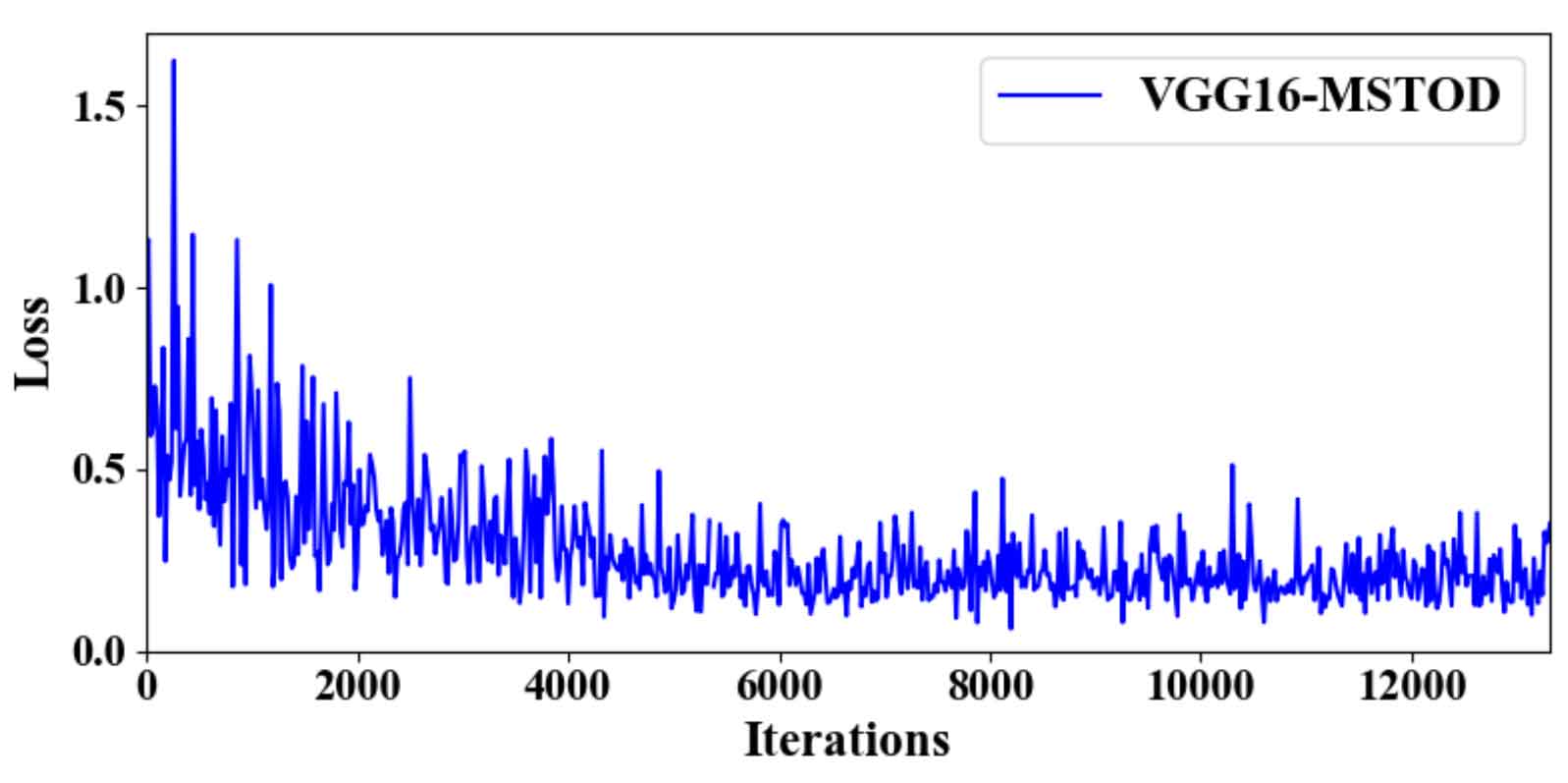
By comparing the loss change process of Fig. 4 and Fig. 5, it can be seen that the initial loss of the pre training parameters using the trained mstod data set is smaller and the loss decreases faster; It can be seen from figures 6 and 7 that the recall rate is decreasing and the accuracy is increasing. It shows that using mstod data set can help the network to identify bucket teeth. However, due to the complex working conditions of the actual data, there was misidentification at the beginning. With the increase of accuracy, the misidentification began to decrease, so the recall rate began to decline. It can be seen from table 2 that the effect of using mstod data set for pre training training set is slightly better than that of using Imagenet data set.
| Pre training parameters | AP | Recall | Precision |
| MSTOD | 0.8024 | 0.8849 | 0.7162 |
| ImageNet | 0.7897 | 0.8781 | 0.5678 |
(3) Model effect test
In this paper, the parameters that have been fine tuned and trained by the actual bucket data set and iterated 8880 times are used for testing. For the model bucket, because the shooting environment is random and multi pose shooting is adopted, there are certain differences between samples. Considering that the bucket working on site will be polluted by materials, the model bucket will be artificially polluted in the experiment to simulate the scene.



The experimental results are shown in Figure 8. In Figure 8, this chapter is divided according to the degree of pollution, which is divided into relatively clean and no pollution on the bucket surface, slight pollution with certain covering and dust on the bucket, and heavy pollution with more attachments and covering on the bucket. The image is tested, and the target detection algorithm is used to detect the bucket teeth.
As can be seen from figure 8 (a), the trained model still has high detection accuracy and positioning accuracy in the face of complex background and bucket with different attitude, which shows that the algorithm has strong robustness. As can be seen from Fig. 8 (b) and Fig. 8 (c), with the aggravation of the pollution degree of the bucket, the size of the detection frame begins to change, and some of them are irregular, but the center of the frame is still on the bucket teeth of the bucket. Therefore, for the model bucket, the algorithm meets the detection requirements.


Due to the material and size problems, the model bucket can not fully simulate the actual bucket, so this paper also tests the actual bucket. This paper tests the excavator bucket collected online and photographed in daily life. As can be seen from Figure 9 (a), the actual working condition is more complex and the bucket tooth detection is more difficult. Therefore, the frame size predicted by some images is irregular and irregular. But generally speaking, for the clear bucket image, the detection effect is good. Fig. 9 (b) is part of the bucket images taken for testing in daily life. Due to construction problems, it can not be clearly photographed, but the model can still recognize the bucket teeth, and the overall effect is OK, but there is still the problem of irregular size of the detection frame.